
Kategoria: AI w biznesie · Status: DRAFT · Data: 2026-04-29
Jeśli kiedykolwiek pomyślałeś przy Claude Code "ok, ale jak ja to mam u siebie poukładać?", ten artykuł odpowiada na to pytanie. Krok po kroku - od instalacji, przez subskrypcję, organizację folderów, konfigurację CLAUDE.md, podpinanie tokenów, ustawianie MCP, aż do automatyzacji w tle przez /loop.
To nie jest tekst, który ogarniesz w 5 minut. Czasu na lekturę zarezerwuj 30-40 minut. Na implementację u siebie - dwa, trzy weekendowe wieczory. Po tym masz setup, który zostaje na lata.
Liczby, komendy i wymagania, które tu znajdziesz, sprawdzałem wobec oficjalnej dokumentacji Anthropic z kwietnia 2026. Jeśli coś się rozjedzie, zostaw mi znać w komentarzu - aktualizuję.
Spis treści
- Co to jest Claude Code i czym się różni od ChatGPT
- Subskrypcje - Pro, Max, API key. Co wybrać?
- Instalacja - Mac, Windows, Linux
- Pierwsze uruchomienie - login, modele, sprawdzenie
- Organizacja folderów - jak ułożyć biznes pod Claude Code
- CLAUDE.md - drugi mózg per projekt
- Tokeny i .env - bezpieczne podpięcie GA4, FB Ads, Sendy itd.
- MCP - rozszerzanie Claude Code o Playwright, GitHub i inne
- Skille - Twoje własne procedury operacyjne
- Slash commands - /loop, /gsd, /init i co jeszcze warto
- Subagenty - delegowanie zadań w tle
- Najczęstsze błędy i jak ich uniknąć
- Co dalej - 30-dniowy plan adopcji
Co to jest Claude Code i czym się różni od ChatGPT
Claude Code to oficjalna aplikacja CLI od Anthropic. Uruchamiasz claude w terminalu i masz asystenta, który operuje na Twoich plikach. Nie kopiujesz tekstów do okna chatu. Claude czyta foldery, edytuje pliki, uruchamia komendy, robi POST do API, zapisuje screenshoty.
Najważniejsze różnice względem ChatGPT:
ChatGPT sprawdza się do jednorazowych pytań i szybkich szkiców. Claude Code sprawdza się do prowadzenia firmy.
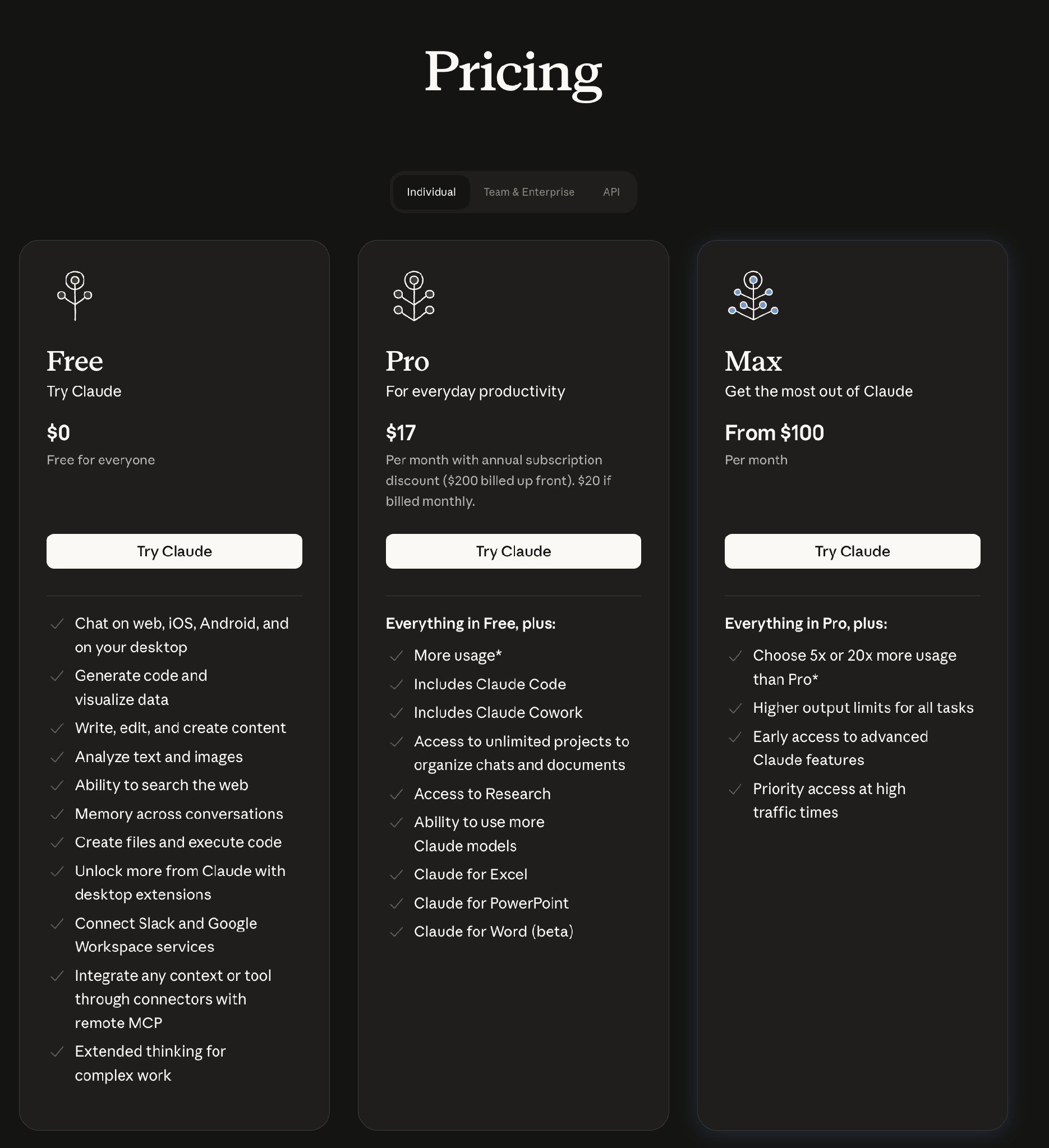
Subskrypcje - Pro, Max, API key. Co wybrać?
Stan na kwiecień 2026, ze oficjalnej dokumentacji Anthropic:
Jedna rzecz, której wielu nie rozumie. Free tier Claude.ai (ten z przeglądarki) nie działa z Claude Code. Anthropic pisze wprost: "the free Claude.ai plan does not include Claude Code access". Pro za $20 (lub $17 przy rozliczeniu rocznym) też nie wystarcza do poważnej pracy - masz na nim dostęp do Opusa 4.8, ale limity wytrzymują dosłownie kilka rozmów dziennie. Sensowne minimum dla foundera to Max od $100.
Co polecam founderom:
- Skip Pro. Wiem, że kuszące ($20 to nic), ale zatkasz limity w pierwszej godzinie i będziesz frustrowany. Sam tego doświadczyłem - Pro to plan "do dotknięcia", nie do pracy.
- Start od Max 5x ($100/mies, ~400 PLN). To jest plan, w którym Claude Code naprawdę działa: pełen Opus 4.8, długie sesje, kilka projektów naraz. Sam jestem tu dzisiaj.
- Max 20x ($200/mies) ma sens dla agencji, deweloperów, code-heavy use. Dla typowego foundera to przesada - dopiero jak codziennie zatykasz $100.
Decyzja API key vs subskrypcja sprowadza się do wolumenu. API jest tańsze, jeśli używasz mało. Jeśli używasz codziennie, subskrypcja wychodzi mniej więcej dwa razy taniej. Plus - subskrypcja ma swoje limity zużycia, ale za to płacisz stałą kwotę z góry. Z API możesz w teorii dostać niespodziewanie wysoką fakturę za miesiąc, jeśli zużycie wystrzeli.
Instalacja - Mac, Windows, Linux
Najszybsza ścieżka. Wszystkie komendy są oficjalne ze strony setupu.
Mac (najprostsze)
Otwórz Terminal i wklej:
curl -fsSL https://claude.ai/install.sh | bash
To instaluje natywny binarny w /usr/local/bin/claude. Bez Node.js, bez homebrew, bez nic.
Alternatywa - jeśli używasz Homebrew:
brew install --cask claude-code
Wymagania: macOS 13.0+, 4 GB+ RAM, Intel albo Apple Silicon.
Po instalacji sprawdź:
claude --version
Powinno zwrócić wersję, np. 2.1.72.
Windows (działa natywnie, bez WSL)
Tutaj funkcjonuje najwięcej mitów. Windows jest wspierany natywnie od kilku miesięcy. Nie potrzebujesz WSL2, nie potrzebujesz żadnego Linux subsystem. Wystarczy PowerShell albo CMD.
PowerShell (rekomendowane):
irm https://claude.ai/install.ps1 | iex
CMD (jeśli wolisz cmd.exe):
curl -fsSL https://claude.ai/install.cmd -o install.cmd && install.cmd && del install.cmd
WinGet (jeśli używasz menedżera pakietów):
winget install Anthropic.ClaudeCode
Coś, czego nie wolno pominąć na Windowsie - zainstaluj Git for Windows (git-scm.com/downloads/win). Claude Code użyje wtedy Git Bash jako shella, a polecenia będą wyglądać jak na Macu. Bez Git Bash fallbackiem jest PowerShell, który ma inną składnię - i część komend rozjeżdża się po drodze.
Najczęstsze problemy na Windowsie (z bugtrackera Anthropic):
- irm w CMD nie działa - to komenda PowerShella. Pamiętaj: PS C:\ = PowerShell, C:\ = CMD.
- && w PowerShellu rzuca "not a valid statement separator" - to składnia Bash, nie PowerShell.
- PATH - czasem instalator nie dopisuje C:\Users\<user>\.local\bin\ do PATH. Wtedy claude nie działa, dopóki nie zrestartujesz terminala albo nie dodasz tego ręcznie.
- Duplikaty - jeśli instalujesz raz przez irm, raz przez WinGet, masz dwa różne claude.exe w różnych miejscach.
Linux
Ten sam skrypt co Mac:
curl -fsSL https://claude.ai/install.sh | bash
Wspierane: Ubuntu 20.04+, Debian 10+, Alpine 3.19+. Można też przez apt/dnf/apk.
Pierwsze uruchomienie - login, modele, sprawdzenie
W terminalu w dowolnym folderze:
claude
Pierwsze uruchomienie poprosi Cię o login. Otworzy się przeglądarka, zalogujesz się do swojego konta Anthropic, wracasz do terminala, gotowe.
Komenda /login w sesji Claude pozwala zmienić konto. /config - ustawienia (motyw, model). /mcp - lista zainstalowanych integracji.
Sprawdź, że wszystko działa:
> kim jesteś?
Powinieneś dostać odpowiedź
Jestem Claude Code, oficjalny CLI od Anthropic...".
Jeśli pojawia się error 401 - login się nie zaciągnął, spróbuj jeszcze raz przez /login.
Organizacja folderów - jak ułożyć biznes pod Claude Code
Ta sekcja decyduje, czy z Claude Code wyciśniesz 30% jego możliwości, czy 100%. Większość założycieli pomija ten krok i potem narzeka, że "to nie działa tak, jak obiecywano".
Reguła jest prosta. Twój biznes powinien mieszkać w jednym folderze - markdowny, pliki robocze, skrypty, dane. Nie rozproszony po Notion, Drive, Dropbox i Google Docs.
Mój układ wygląda tak (możesz adaptować):
~/Pliki/Asystent/
├── CLAUDE.md # Główne instrukcje dla Claude'a
├── .env # Tokeny do API (gitignored!)
├── Marketing/ # Wszystko marketingowe
│ ├── CLAUDE.md
│ ├── blog/
│ ├── linkedin/
│ ├── youtube/
│ ├── mailing/
│ ├── reklamy/
│ ├── ebooki/
│ ├── lp/
│ ├── strategia/
│ ├── pomysly/
│ ├── cli/ # Skrypty bash do GA4, FB Ads, Sendy
│ └── case-studies/
├── Konferencje/ # Kursy, szkolenia, wystąpienia
│ ├── kursy/
│ ├── szkolenia/
│ └── wystapienia/
├── Hetzner/ # Skrypty deploy, infrastruktura
├── Investowanie/ # Portfel, plany (gitignored)
├── Dziennik/ # Codzienne notatki (gitignored)
└── Strategia/ # Wizja, finanse, holding
Nazwy folderów po polsku - bez problemu. Claude czyta polskie znaki.
Cztery rzeczy, które naprawdę się tu liczą:
- Jeden root - cała firma w jednym katalogu nadrzędnym. Nie pięć różnych dysków, nie połowa w chmurze.
- CLAUDE.md w każdym poddrzewie projektu - jeśli projekt ma więcej niż dwa pliki, daj mu instrukcję dla Claude'a (o tym za chwilę).
- .env tylko w roocie - tokeny w jednym miejscu, dostępne z każdego skryptu.
- Git - git init daje Ci kopię zapasową i historię. Foldery prywatne (Investowanie, Dziennik) wpisz do .gitignore.
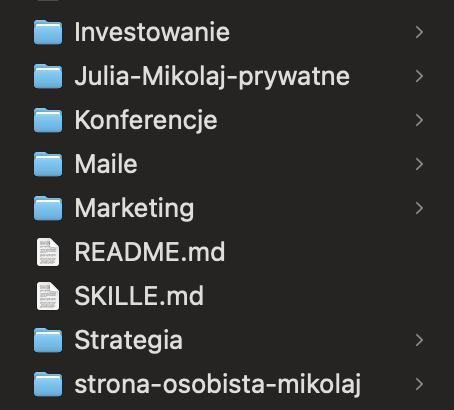
Mój folder główny po wprowadzeniu CLAUDE.md w każdym podfolderze. Marketing, Konferencje, Strategia, Investowanie, Julia-Mikolaj-prywatne. Każdy z tych folderów ma swój `CLAUDE.md`, w którym Claude od razu wie, co tam mieszka i jak ma się tam zachowywać.
CLAUDE.md - drugi mózg per projekt
Jeśli mam wskazać jedną rzecz, która odróżnia "działa kiepsko" od "działa świetnie", to jest to plik CLAUDE.md. Instrukcja dla Claude'a, którą wczytuje automatycznie za każdym razem, gdy uruchamiasz go w danym folderze.
Występuje na dwóch poziomach:
- ~/.claude/CLAUDE.md - globalny, działa dla wszystkich projektów (Twoje preferencje, styl, co robić, czego nie)
- <projekt>/CLAUDE.md - lokalny, specyficzny dla danego projektu
Tak wygląda mój główny CLAUDE.md (skrócony):
# CLAUDE.md
## Co to jest
Repo asystenta Mikołaja Brunki - właściciela NoCodeWork.io.
Materiały do wielu projektów: kursy, content, narzędzia CLI, infra.
## Język
Wszystkie treści po polsku z diakrytyką (ą, ę, ś, ć, ź, ż, ó, ł, ń).
## Struktura
Każdy folder to osobny projekt z własnym CLAUDE.md.
| Folder | Opis |
|---|---|
| Marketing/ | Master folder marketingowy |
| Konferencje/ | Kursy, szkolenia, wystąpienia |
| Hetzner/ | Serwer + Coolify + n8n dla klientów |
## Konwencje
- Pliki markdown z frontmatter YAML dla artykułów
- Skrypty bash w Marketing/cli/ - credentiale w .env
- HTML kursu - vanilla JS, zero frameworków
Co wpisać w CLAUDE.md na poziomie projektu (np. Marketing/CLAUDE.md):
- Mapę "chcę X → wejdź do Y" (gdzie co leży)
- Workflow content (kroki: pomysł → plan → tworzenie → publikacja → pomiar)
- Dostępy techniczne (URL-e, base ID, jak autoryzować)
- Konwencje (nazwy plików, frontmatter, format)
- Status snapshot (co już zrobione, co jest do zrobienia)
Mój zwyczaj - jeśli coś tłumaczę Claude'owi po raz drugi, od razu wpisuję to do CLAUDE.md. To skraca wszystkie kolejne sesje.
I jeszcze jedno - CLAUDE.md nie musi być "ładnie napisany". Mój wygląda jak notatki robocze. Claude i tak czyta. Liczy się treść, nie estetyka.
Tokeny i .env - bezpieczne podpięcie GA4, FB Ads, Sendy itd.
Jeśli chcesz, żeby Claude wyciągał Ci dane z GA4, Meta Ads, Sendy itd., potrzebujesz tokenów. Trzymaj je w jednym pliku .env w głównym folderze, oczywiście gitignored.
Tak wygląda mój .env (z anonimizowanymi wartościami):
# Google Analytics
4GA4_PROPERTY_ID=123456789
GA4_SERVICE_ACCOUNT_FILE=/Users/.../sa-key.json
# Meta Ads
(Facebook)FB_AD_ACCOUNT_ID=act_xxxxx
FB_ACCESS_TOKEN=EAA...
# Sendy
SENDY_URL=https://sendy.twojadomena.pl
SENDY_API_KEY=xxxxx
SENDY_LIST_ID=xxxxx
# NocoDB (content hub)
NOCODB_URL=https://nocodb.twojadomena.pl
NOCODB_API_TOKEN=xxxxx
# OpenAI (jeśli używasz)
OPENAI_API_KEY=sk-...
# Anthropic (jeśli przez API)
ANTHROPIC_API_KEY=sk-ant-...
Cztery zasady bezpieczeństwa:
- .gitignore musi zawierać .env. Po dodaniu .env-a od razu sprawdź git status, że nie wskakuje na listę zmian.
- Tokeny nigdy nie trafiają do CLAUDE.md ani do plików, które są na gicie.
- Tokeny FB Ads / GA4 mają datę ważności. Dla FB rób System User Token (permanentny), nie zwykły, który wygasa po 60 dniach.
- Skrypty bash ładują .env przez source .env na początku - jedna linijka, dalej masz wszystko dostępne.
Sam Claude nie widzi .env automatycznie. Ale jeśli powiesz "uruchom Marketing/cli/ga4.sh visitors 7", skrypt sam załaduje .env i wyśle request do API. Claude zobaczy tylko output - "wczoraj było 412 wejść". Tokenów nie dotyka.
To jest świadoma decyzja. Dzielisz się wiedzą o danych (liczby, raporty), ale nie udostępniasz kluczy. Jeśli ktoś kiedyś przejmie Twoją sesję Claude, nie wyciągnie Ci tokenów.
Krótka instrukcja, skąd wziąć poszczególne tokeny:
- GA4: console.cloud.google.com → Service Account → Klucz JSON. Service account musi być dodany jako Viewer w GA4 Admin.
- Facebook Ads: business.facebook.com → Marketing API Tools → Use cases → Tools → Generate Token. Uwaga - nie generuj z Graph API Explorer, bo nie ma tam wszystkich permissions.
- Sendy: panel Sendy → Settings → API key.
- NocoDB: UI NocoDB → swój profil → API Tokens → Create.
Jeśli się zgubisz, poproś Claude'a: "pomóż mi wygenerować token do GA4 - prowadź mnie krok po kroku". W tym jest naprawdę dobry.
MCP - rozszerzanie Claude Code o Playwright, GitHub i inne
MCP (Model Context Protocol) to protokół, który pozwala Claude Code'owi rozmawiać z innymi narzędziami. Standard otwarty, dziesiątki gotowych "MCP serverów" do popularnych usług.
Najprzydatniejsze MCP dla foundera:
Dokładne komendy instalacji znajdziesz w katalogu MCP Anthropic (gotowe paczki npm) albo w oficjalnym katalogu MCP servers. Format jest stały - claude mcp add <nazwa> <komenda-uruchamiająca>. Nazwy paczek mogą się zmieniać, więc zawsze sprawdzaj aktualny stan w katalogu zamiast kopiować z artykułu.
Jak dodać (przykład - Playwright):
claude mcp add playwright npx @playwright/mcp@latest
Po tym w sesji Claude możesz powiedzieć "otwórz nocodework.io w przeglądarce i zrób screenshot strony głównej" - i to działa. Każdy MCP ma podobny pattern - jedną komendę instalacji + restart sesji.
Lista zainstalowanych MCP w sesji:
/mcp
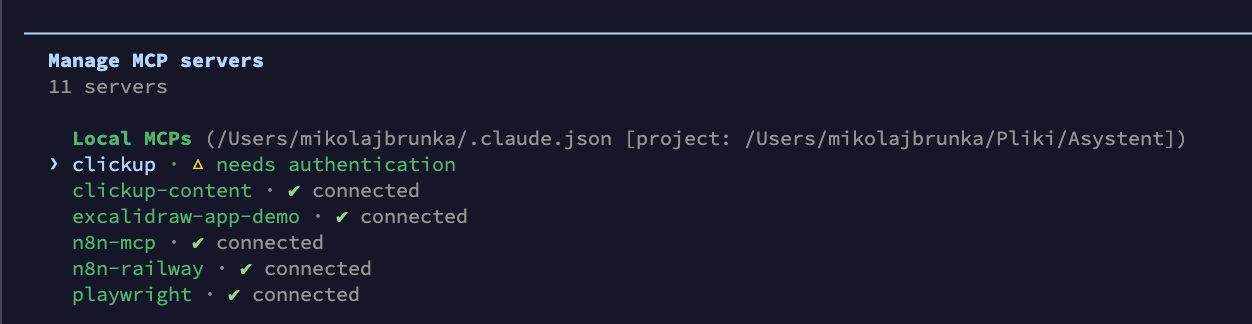
Lista MCP serverów, które mam wpięte. Widać między innymi `clickup`, `clickup-content`, `excalidraw-app-demo`, `n8n-mcp`, `n8n-railway`, `playwright`. Każdy z nich rozszerza Claude'a o nowy obszar - od tworzenia diagramów po sterowanie przeglądarką.
Z mojej praktyki - Playwright MCP otwiera drogę do narzędzi, które mają słabe albo żadne API. Hotjar to klasyczny przypadek. Mogę powiedzieć Claude'owi "zaloguj się do Hotjar, otwórz dashboard, zrób screenshot, opisz mi metryki" - i tak się dzieje. Tak samo z każdym innym dashboardem, do którego masz login w przeglądarce.
Skille - Twoje własne procedury operacyjne
Skille to "kompetencje", które dodajesz do Claude'a. Każdy skill to folder w .claude/skills/<nazwa>/ z plikiem SKILL.md w środku. Claude automatycznie ładuje skill, jeśli zadanie pasuje do jego opisu.
Przykładowy skill (.claude/skills/n8n-automation/SKILL.md):
- - -
name: n8n-automation-workflow
description: Tworzenie i debugowanie workflow na własnej instancji n8n
- - -
# n8n Automation Workflow
## Kiedy używać
Gdy user prosi o stworzenie/edycję/debug workflow n8n.
## 9 udokumentowanych pułapek1.
WAF na Twoim API blokuje requesty bez właściwych nagłówków
2. $env.X nie działa w nodach - użyj $vars albo expression
3. Credentials nie importują się z wartościami...[...]
## Workflow tworzenia
1. Sprawdź czy MCP n8n-mcp jest aktywny
2. Wczytaj nazwy istniejących workflow przez n8n_list_workflows
3. ...
Po co w ogóle pisać skille? Trzy powody:
- Za każdym razem, gdy musisz Claude'owi tłumaczyć "tu robi się tak" - to znak, że to jest skill. Zapisujesz raz, używasz zawsze.
- Claude wczytuje skille automatycznie, kiedy zadanie pasuje do opisu. Nie powtarzasz.
- Skille są przenośne - wrzucasz na gita, dzielisz z zespołem, zachowujesz ciągłość wiedzy w firmie.
Konkretny przykład z mojego repo - cron-dispatcher w n8n. Cykliczne zadanie dodaję przez POST do NocoDB, a n8n czyta tabelę co minutę i dispatchuje akcję. Zapisałem to jako skill z dziewięcioma pułapkami i przykładami curl. Dziś mówię Claude'owi "dodaj cykliczne zadanie 'sprawdź briefy o 8:00'" - i on robi POST z poprawnym User-Agent, formatem cron i wszystkimi wymaganymi polami. Bez przypominania.
Lista moich własnych skilli w folderze `.claude/skills/`. Każdy ma własny folder z plikiem `SKILL.md` w środku. Widać tu m.in. `dziennik` (skill do prowadzenia dziennika) i `humanizer` (skill do usuwania śladów AI z tekstów). Drobne, jednoekranowe pliki, ale zmieniają cały sposób rozmowy z Claude'em.
Slash commands - /loop, /gsd, /init i co jeszcze warto
Slash commands to skróty wewnątrz sesji Claude. Część jest wbudowana, własne też możesz dopisywać.
Wbudowane, które warto znać:
Najciekawsza dla foundera jest /loop:
/loop 5m sprawdź czy mój build na Coolify się zakończył
Claude co 5 minut wykonuje to polecenie, dopóki sam nie zamknie pętli (np. gdy build się skończy). Pasuje do pollingu, czekania na deploy, monitorowania metryk.
/loop sprawdź co jakiś czas przychodzące maile w priorytetowej skrzynce
Bez interwału - Claude sam dynamicznie ustawia pacing.
Własne slash commands to plik .claude/commands/<nazwa>.md z instrukcją w środku. Wpisujesz /<nazwa> w sesji - i Claude wykonuje to, co opisałeś.
Mój przykład: /post-linkedin - generuje trzy warianty posta LinkedIn na bazie ostatnio zmienionego pliku w Marketing/linkedin/.
Druga rzecz, którą warto sprawdzić, to ekosystem /gsd (Get Stuff Done) - zewnętrzny pakiet skilli i komend do prowadzenia projektów (planning, execution, debugging) z Claude Code. Instalujesz przez plugin marketplace albo manualnie. Sprawdza się przy większych projektach.
Subagenty - delegowanie zadań w tle
Subagent to "drugi Claude", który dostaje od Ciebie konkretne zadanie i wraca z wynikiem. Każdy ma własne 200k tokenów kontekstu i swoje narzędzia, niezależne od Twojej głównej sesji.
Po co to komu? Trzy zastosowania:
- Research. "Przeszukaj cały Marketing/ pod hasłem 'lider zmiany'" - subagent przegląda, wraca z pięcioma cytatami. Twoja główna sesja nie zużywa kontekstu na 50 plików.
- Praca równoległa. Możesz odpalić trzy subagenty jednocześnie do różnych zadań i odebrać wyniki, gdy będą gotowe.
- Praca w tle. Subagent działa, podczas gdy Ty robisz coś innego.
Jak to wygląda w praktyce:
> Przeszukaj wszystkie posty w Marketing/linkedin/ z ostatnich 6 miesięcyi znajdź te, które mają najwięcej komentarzy. Daj mi top 5 z analizą hooków.
Claude może to zrobić sam, ale jeśli widzi, że to wymaga przeglądania wielu plików, automatycznie odpali subagenta. Możesz też wymusić: "odpal w tym subagenta typu Explore".
Najczęstsze błędy i jak ich uniknąć
Po pół roku codziennego użycia, oto pułapki, w które wpadłem:
1. Brak CLAUDE.md = Claude działa "z głowy"
Jeśli nie masz CLAUDE.md, Claude generuje generyczne odpowiedzi. Każdy projekt potrzebuje minimum 50-linijkowego pliku.
2. Wszystko w jednym chat'cie
Nie. Każdy projekt = osobna sesja claude w jego folderze. Inaczej Claude miesza konteksty.
3. Tokeny w plikach
Tokeny tylko w .env, .env tylko w gitignore. Sprawdź git status po dodaniu .env.
4. Brak `.env.example`
Jeśli pracujesz z zespołem, dodaj .env.example z nazwami zmiennych (bez wartości). Inaczej zespół nie wie, co podpiąć.
5. Pisanie 100 linijkowego prompta zamiast skill'a
Jeśli powtarzasz tę samą instrukcję 3 razy, zrób z tego skill. Inaczej tracisz tokeny i czas.
6. Niezrozumienie różnicy ChatGPT vs Claude Code
Pisanie do CC tak, jak do ChatGPT ("napisz mi post LinkedIn") - dostajesz średnie wyniki. Pisanie z kontekstem ("napisz post LinkedIn na bazie mojego top posta z marca, w stylu Marketing/linkedin/CLAUDE.md") - dostajesz świetne wyniki.
7. Nieaktualizowany CLAUDE.md
Plik się starzeje. Co miesiąc go odświeżaj. Inaczej Claude działa na nieaktualnym kontekście.
8. Brak gita
Jeśli nie masz gita, każdy "Claude usunął mi plik" jest bolesny. Z gitem - git checkout i wracasz.
9. Strach przed terminalem
Pierwsze 3 dni są najgorsze. Po tygodniu jest naturalnie. Po miesiącu nie chcesz wracać.
Co dalej - 30-dniowy plan adopcji
Jeśli chcesz zacząć od jutra, oto plan rozłożony na cztery tygodnie:
Tydzień 1 - setup:
- Dzień 1: instalacja, login, pierwsza rozmowa.
- Dzień 2-3: struktura folderów Twojego biznesu w jednym katalogu.
- Dzień 4-5: główny CLAUDE.md (50-100 linii: opis firmy, projektów, konwencji).
- Dzień 6-7: wgraj 3-5 projektów (foldery z plikami markdown - notatki, plany, briefy).
Tydzień 2 - tokeny i integracje:
- Dzień 8-9: wygeneruj tokeny GA4, Meta Ads. Dodaj do .env.
- Dzień 10-11: pierwszy skrypt CLI (np. do GA4). Poproś Claude'a, żeby Ci go napisał.
- Dzień 12-14: pierwszy MCP - Playwright albo GitHub.
Tydzień 3 - workflow operacyjne:
- Dzień 15-17: każdy istotny projekt dostaje swój CLAUDE.md.
- Dzień 18-21: pierwsze skille. Wybierz 2-3 zadania, które robisz często, i zapisz jako skill.
Tydzień 4 - automatyzacje:
- Dzień 22-25: pierwsza /loop - cykliczne zadanie (monitor build'u, analiza dziennej analityki).
- Dzień 26-28: optymalizacja CLAUDE.md - co działa, co nie.
- Dzień 29-30: jeśli wszedłeś na Pro testowo, czas na decyzję - przesiadka na Max 5x ($100/mies). Jeśli już jesteś na Max 5x, oceniasz: zostać czy iść w Max 20x.
Po miesiącu masz setup, którego naprawdę używasz.
Podsumowanie
Claude Code dla foundera nie jest kolejnym narzędziem AI w stacku. To zmiana filozofii pracy - z "każde narzędzie ma swoje pliki" na "wszystkie pliki są moje, a Claude rozumie kontekst całego biznesu".
Setup zajmie Ci jeden, dwa weekendy. Później oszczędzasz średnio 15-20 godzin tygodniowo. Matematyka mówi sama za siebie.
